- I should be able to explain, in fractal terms (a gradient from simple to reasonably detailed), whatever thing that I learned.
- This space should be free of any anxiety about asking stupid questions.
- This space should be an append-only record of thoughts and learnings.
Few new things. Doing the following is doing a type assertion in Go:

Learned about buffers today also. Buffers are a temporary storage location to transfer data from one location to another. Buffered I/O is when data is first read from or written to a buffer, and then transferred over to the end destination. It kind of reminds me of a bus - the bus is a "temporary storage location" that transfers passengers from point A to B.
Been working through Writing an Interpreter in Go - it'll be good for the next Electric upgrade that I'm planning.
Something I found confusing was interfaces. Apparently that's a pretty common confusion. I was looking at this code here:

I was getting confused why a pointer to ast.LetStatement is a valid return type for a function with return type ast.Statement. It's because the pointer to ast.LetStatement actually implements the ast.Statement interface, not ast.LetStatement itself. That's pretty interesting, and it makes sense from the code? ast.LetStatement just holds information about the Let node, but the actual methods belong to the pointer.
Was working through the Svelte tutorial, and saw an example of a labeled statement. Svelte uses the dollar sign $ to denote reactive elements e.g. $: double = count * 2.
Also while reading this section, realized that Svelte probably uses Proxy under the hood? The Svelte tutorial says that reactive behavior won't be triggered unless assignment occurs, which suggests that Svelte hijacks the set method. Not sure - need to come back to this hunch later.
Kind of cool how many things are coming together. In this section of the Svelte tutorial, there's export let answer = 'a mystery'. Which, as I learned a couple days ago with minipack, the export of the module will be an object like answer: 'a mystery'.
I've always wondered how conditional rendering works. The Svelte tutorial has this snippet of Svelte code:

...which the Svelte compiler compiles into...
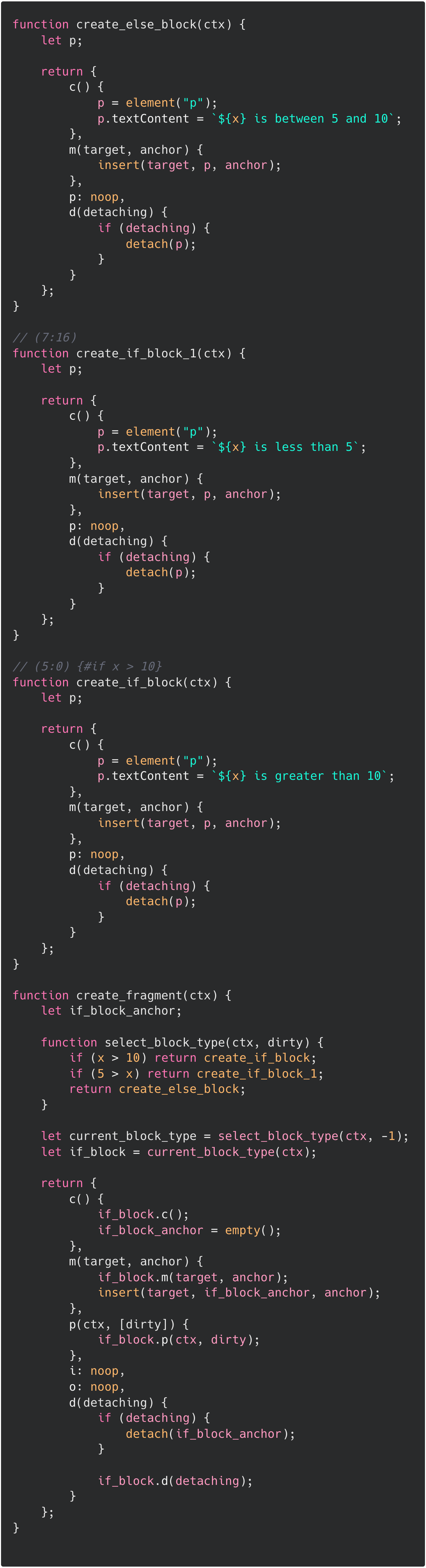
So it seems like Svelte creates functions that return fragments for each branch, and calls them based on the value of x. The dirty flag is there to inform when the fragment should be re-rendered.
First time hearing about Javascript's runtime model - the event loop. This is a pretty different model than what I'm used to as a Python programmer (primarily). This is probably why callbacks are so key to Javascript programming - the callback is added to the message queue and it may be executed long after the function that scheduled it has been popped off the stack.
I did not realize that the second parameter to setTimeout was a minimum time guarantee. This is because of the event loop. If the message queue is empty, then the callback is executed immediately at the specified time. But if the message queue is occupied with a long-running task, the callback will have to wait until the previous task is finished since the event loop can only run one task at a time.
Now everything is so much clearer! It makes sense why responses to clicks are delayed. It's because there are other tasks in the message queue that have higher priority, so whatever callback is invoked by a click will have to wait until the other tasks are finished.
It also makes sense why Promises are a big deal. Why wait until the response has arrived? Just wait until the response arrives, and slap the callback into the message queue.
This all began because I was going through this small tutorial about building a web framework. I'll have to write more about it later, but it goes into "microtasks" which work on a different "schedule" than the main message queue.
Wrote some learnings down in the AlternateTimelines post.
Learned a bit about Byzantine faults; where faults occur because of nodes that respond.. A system is called Byzantine-tolerant if it continues to operate correctly despite nodes
ASCII, UTF-8, Unicode. What blends them all together? There's this nice line in Dive Into Python: "Bytes are bytes; characters are just an abstraction."
Unicode is just a standardized mapping from characters to codes - it's completely arbitrary. The codes are called codepoints. UTF-8, UTF-16, UTF-32 are all just representations of the codepoints in 8, 16, and 32 bits, respectively. There are only about 1.1 million codepoints currently, so 4 bytes is enough to encode all the codepoints.
Where is ASCII in the picture? ASCII was the character encoding standard before UTF came around - but it was limited to alphanumeric and punctuation symbols only. The UTF encodings are like a subset of ASCII - this is by design, of course. UTF-8 was designed for backwards compatability with ASCII.
In Python, b"" denotes a byte string and "" denotes a Unicode string. Of course, the machine sees both of these two as bytes, so it's really a UX thing. b"" denotes data that needs to be explicitly decoded/encoded, whereas "" is already abstracted as a character/text string.
Synchronizing clocks is tricky business. It's hard to notice when, for instance, an NTP client is misconfigured and your software is drifting farther and farther from reality. So it's important to do checks on your clock offsets.
Learned about clocks and time. These days, computers have two different kinds of clocks: a time-of-day clock and a monotonic clock. The difference between the two are implicit in their names. A monotonic clock always moves forward (so it's better for measuring durations), but the actual value of the clock means nothing. With time-of-day clocks, since they're synchronized with the Network Time Protocol (NTP), they are more suitable for marking points in time.
Amending my understanding of snapshot isolation. I said yesterday that snapshot isolation is a natural extension of read committed isolation. That is true in some sense - on the level of going from mechanical to logical consistency. But snapshot isolation is about preventing problems where writes happen right in between reads. The bank account scenario isn't prevented in read committed isolation because there are no dirty reads or writes; the first read reads the committed $500 balance, and the second read also reads the committed $400 balance. But it's because the first read happens just before or right at the moment the write begins that you get logical consistency problems.
Moving on. Learned about MVCC (multi-version concurrency control), which is a way of implementing snapshot isolation. In read committed isolation, you need to keep track of only two snapshots per object - the committed value and the overwriting value. But for snapshot isolation, you need a longer lookback of snapshots because some in-progress transaction might need to see the database at different points in time.
In MVCC, each transaction is given a unique id. These ids are incremented for each transaction, hence they're monotonically increasing. On writes, the data that is written by a particular write is tagged with its id. On reads, only the transactions that satisfy the following criteria are visible:
- transactions that are not in-progress
- transactions that are not aborted
- transactions with a later transaction ID
Read committed isolation and snapshot isolation mainly address concurrent reads and writes. What about concurrent writes? One of the problems that can occur is the lost update problem. An application operates on a read-modify-write cycle (read some value, modify it, write it back) can lead to lost updates - when two transactions execute a read-modify-write cycle, one of the writes can be overwritten by the other.
Kleppman jots down five ways of preventing lost updates:
- Atomic write operations. Put an exclusive read + write lock on the object being read during the read-modify-write transaction, so that no other operations can read it until the entire cycle is committed. This is handled on the level of the database.
- Explicit locking. Do the above, but DIY - put it in your application code.
- Automatic detection. Allow concurrent read-modify-writes, but detect when a lost update occurs. Abort and retry if lost update is detected.
- Compare-and-set. Update only if the value has not updated since you last read it. Abort and retry if the value is different. Almost like a read-modify-read-write operation. This method can be error-prone because the second read could read from an old snapshot.
- Conflict resolution. This idea is most similar to automatic detection. When you have replicas, preventing lost updates gets harder. Locks + compare-and-set assume a single source of truth - so these methods can work well with single-leader replication. But with multiple leader or leaderless replication, there are multiple "sources of truth", so they might not work well. The "fix" is to resolve conflicts.
Also learned about write skew. Write skew is like a generalization of lost updates for multiple objects i.e. lost updates when multiple objects are being written over.
An example of write skew: the logical constraint is that at least one doctor needs to be on call for any shift. Alice and Bob are the only two doctors at Hospitalia, and they are both sick. When they both cancel their shifts, each transaction independently checks that there is at least one doctor on call, and then goes through with the cancel if that is the case. But now there are no doctors on call! This example makes it clear that write skew is a generalization of lost updates for multiple objects, because two objects are being written here (the onCall boolean for Alice's row and Bob's row) and there's clearly a logical conflict.
Finally, the strongest isolation label: serializable isolation. Serializable isolation guarantees that for any group of transactions, there exists some serial ordering of those transactions such that any concurrent execution is guranteed to produce the same result as executing them in this serial ordering.
Kleppman outlines three implementations of serialization isolation: (1) actual serial execution, (2) two-phase locking (2PL), and (3) serializable snapshot isolation (SSI).
Actual serial execution means preventing concurrency from the get-go: execute only one transaction at a time in a serial order on a single thread. Obviously, for interactive use cases, serial execution can be seriously slow. In the doctor example, some interaction occurs between the application and the database:
- Database: the number of doctors on call are retrieved
- Application: check if the retrieved value is greater than 1. If so, execute step 3.
- Database: conditional on step 2, cancel Alice/Bob's shift.
Also, if your data is partitioned, then serial execution can be problematic if you write across different partitions. Every partition that is touched by a transaction needs to be in lockstep, which kind of defeats the purpose of partitioning in general.
Two-phase locking (2PL) enforces greater lock constraints. Namely, writers can also block readers, and vice versa (in snapshot isolation, writers block writers and readers block readers. No cross contamination):
- "If transaction A has read an object and transaction B wants to write to that object, B must wait until A commits or aborts before it can continue."
- "If transaction A has written an object and transaction B wants to read that object, B must wait until A commits or aborts before it can continue."
In 2PL, there's another kind of lock called a predicate lock. A predicate lock is a lock that is applied to objects that match a specific condition. This kind of lock is specifically for preventing phantoms - as such, predicate locks apply to objects that may not even exist in the database yet. It works like this:
- If transaction A wants to read objects that satisfy some predicate, it must acquire a shared predicate lock on the satisfying objects.
- If transaction A wants to read objects that satisfy some predicate, but transaction B is writing to any of those objects, transaction A must wait until B releases its lock.
- If transaction A wants to write to some objects, then it must first check if any of those objects are under existing predicate locks. If so, then transaction A must wait.
In some sense, 2PL is like a relaxation of actual serial execution - only the transactions that are possibly affected by concurrent execution are addressed.
Serializable snapshot isolation (SSI) is "smart" snapshot isolation: an additional algorithm is added for detecting serialization conflicts. Because snapshots reflect old information, the simple "trick" is to simply track when a transaction ignores another transaction's writes, and to abort when there are any ignored instances.
Learned about snapshot isolation, which is a stronger guarantee than read committed isolation. Snapshot isolation primarily protects against read skew, which is something that can't be prevented with pure read committed isolation. I can't come up with a good definition for read skew right now, so I'll just explain with the example given in the textbook.
I have two bank accounts, with $500 in each of them. Just after I check the balance for account A (I see $500), Helena transfers $100 from account B to account A. Afterwards, I check the balance in account B, and see $400! Of course, I could just check account A again to confirm that there is a total of $1000 across both accounts - but the point is that I read before and after a transaction, where one of the values I read was "old" and the other was "updated". In other words, consistency is violated: the invariant consistency property being that I have $1000 total across both accounts.
Snapshot isolation guarantees that reads that are part of the same transaction will read from the last consistent state of the database. In the example above, it means that the two reads will return ($500, $500) rather than ($500, $400).
Notice how this is really an extension of read committed isolation. Read committed isolation guaranteed no dirty reads - you can only read data that has been committed. Snapshot isolation guarantees no dirty reads on the level of transaction reads (i.e. a series of reads as one unit) - you can only read data that is both consistent and has been committed.
Happy turkey day.
I learned that position:sticky requires you to define some kind of "fixed point". For example, you need also define left:10px.
Saw this description of CSS that was incredibly clarifying: "The properties we write are inputs, like arguments being passed to a function. It's up to the layout algorithm to choose what to do with those inputs." (from Josh Coumeau).
So just like x means different things in (lambda x (+ x 1)) and (lambda x (concat "hello " x)), saying width:100px implies different layout behavior depending on the layout algorithm that is used.
Also: apparently img is an inline element in the normal flow layout algorithm? That's nuts and kind of stupid - but there is definitely some historical context I am missing here.
Yesterday, I read about ACID guarantees. Today, I started reading about different levels of isolation. In the ideal scenario, we'd like to have serializable isolation: "any concurrent execution of a set of Serializable transactions is guaranteed to produce the same effect as running them one at a time in some order" (from the PostgreSQL documentation). But the world isn't perfect, so we have differing degrees of isolation.
Starting with the weakest guarantee: read committed isolation. It guarantees:
- No dirty reads. You can only read data that has been committed (you cannot see half-finished data.)
- No dirty writes. You can overwrite only data that has been committed.
Most widely available databases provide read committed isolation as a default. In implementation, dirty writes are prevented using row-level locks: when a transaction wants to modify an object, then it must first acquire the lock for that object. If another transaction has already acquired the lock, it must wait until the lock is released.
Dirty reads can be prevented using the same lock - wait until the lock is released before reading - but this typically causes poor response times. Imagine having to wait god-knows-how-long until a write is finished! Instead, the space-time tradeoff is employed: just keep track of the "old value" and return that until the new value overwrites the old one.
Started reading about transactions. A transaction is a grouping of read & write operations as one logical unit.
What problem do transactions address? Fault-tolerance. There are a lot of things that can go wrong when using a database e.g. the database software/hardware might crash during a write, multiple clients may write to the database concurrently, etc.
Transactions with ACID guarantees - atomicity, consistency, isolation, durability - are a first step towards a fault-tolerant database.
- Atomicity. A transaction that executes multiple operations is either executed in full, or not at all. A transaction that fails halfway through is rolled back.
- Consistency. Transactions must preserve logical consistency e.g. credits and debits must zero out. Consistency is more a property of the application than the database itself.
- Isolation. Transactions that execute concurrently are isolated from one another - they do not step on each other's toes. For example, a counter that is concurrently incremented by two clients must change by +2, not +1.
- Durability. A completed transaction is committed forever.
The definitions for atomicity and isolation implicitly refer to transactions that modify multiple objects. But they can refer to single objects also. Imagine you're writing the entirety of Moby Dick to a database. If someone pulls the plug on the database during the write, what happens to the unfinished write? What if a client tries to read the value while the write is ongoing? Transactions on single objects, though, are much simpler than the same on multiple objects, so most databases provide atomic operations on single objects for free.
Learned about partitioning. At first, I was confused about how partition and replication could be implemented together - what if two copies of the same partition end up on the same node? But I realized that partitioning + replication isn't creating multiple copies of shards, and then randomly placing them onto nodes. It's less rAnDoM.
Think about partitions as a miniature database. Applying replication to this miniature database, for all miniatures databases, is basically replication + partitioning. Replication paradigms all hold on the level of this miniature database (i.e. the partition).
For datasets with only a primary key, you can naively assign a key range to each partition e.g. A-J goes to partition 1, K-M goes to partition 2, M-Z goes to partition 3. Key ranges need not be evenly spaced - in fact, the keys themselves are probably not evenly distributed, so the partition boundaries are probably also not going to be even.
Instead of staying in the original "key distribution" by partitioning by key range (the distribution is likely to change), you can also transform the distrbution into a uniform distribution by using a hash function. In the hash space, the keys are distributed evenly. The downside of this is that you lose all "semantic" information about the key; in effect, this means you lose the ability to do efficient range queries, because querying a range will likely mean querying from multiple partitions due to how the hash function re-distributes the keys in the hash space.
Partitioning for datasets with secondary indexes is slightly more complicated; there is another axis across which you must slice, and that axis may be completely orthogonal to your primary key. There are generally two approaches: (1) by document and (2) by term.
Partitioning by document comes from treating the partition like a mini-database. The secondary key is "partitioned" such that the secondary keys are localized to partitions. For example, if the primary key is the time the item was sold, and the primary key is the color of the item - then the secondary index in each partition will map the color "red" to items that are in its partition only. The upside of this approach is that writes are quick - adding a new entry means adding only to the secondary index of the partition of which the new entry is a part. The downside is that reads are expensive - all partitions must be queried in order to retrieve all the entries that are associated with "red", for example.
Instead of localizing by partition, partitioning by term instead partitions the secondary index itself. Each partition holds a slice of the secondary index e.g. partition 1 holds "red" and "blue", partition 2 holds "green" and "silver", etc. The tradeoffs with this approach is the opposite from those of partitioning by document: reads are quick, writes are expensive. A single write may affect multiple partitions.
As your data grows, the distribution and demands of your data also evolve. Hence we need to be able to rebalance our partitions effectively. The three approaches outlined by Kleppman are (1) fixed number of partitions, (2) dynamic partitioning, and (3) proportional partitioning. Fixing a number of partitions means determining a number of partitions beforehand, and just allocating your data across those partitions. Dynamic partitioning involves dynamically splitting off and merging partitions while keeping each partition within some minimum and maximum data size range. (e.g. split into two partitions when data exceeds 10Gb). Proportional partitioning means fixing a number of partitions per node, rather than per-entire-system.
With our data split apart, how do we know which node to look for a specific piece of data? Here are a few approaches:
- Clients connect to nodes directly. The node that receives the request reroutes the request to the node that contains the requested data i.e. every node knows where every piece of data lives.
- Clients connect to a routing tier first. Kind of a like a reverse proxy.
- Imbue the clients with the knowledge of what data lives in which partitions. Offload the routing responsibilities to the client.
Reading about other replication paradigms like multi-leader and leaderless replication.
One of the downsides of the single-leader paradigm is that all writes are routed through a single node (the leader). Multi-leader replication extends single-leader replication by allowing writes to be routed through multiple nodes. You are trading off better write performance for more complexity - specifically, the complexity of having multiple sources of truth and having to resolve conflicts between them. Now, two different writes on the same data could occur concurrently!
How are conflicts resolved? Like life, there are broadly two approaches: either avoid it, or face it.
Methods for conflict avoidance are similar in spirit to those used for read-after-write consistency: assign a unique leader for each kind of data or each user. This boxes off different sources of conflict - which means less chances for conflict to occur.
On the other hand, facing conflict can be trickier. Broadly speaking, you can resolve conflicts by either (1) picking a winner or (2) seeking a compromise. An example of picking a winner is assigning a unique ID to each write, and just picking the write with the highest ID upon conflicting writes. Unfortunately, just like in real life, picking a winner is prone to losing data - data that should be in the history books but isn't because of a naive approach. Instead, try seeking a compromise! It's harder to do, but you retain as much information as possible. Some automatic conflict resolution technologies include conflict-free replicated datatypes (CRDTs) and operational transformations (OTs).
A replication topology is the structure of how replications are carried out among different leaders in a multi-leader replication framework. Three examples are the circular topology, star topology, and the all-to-all topology. The circular topology passes on replication data in a one-dimensional, circular fashion. The star topology is an extension of single-leader replication, but on the leader level. All-to-all topology is a totally connected network - every leader is connected to every other leader.
Finally, leaderless replication. Leaderless replication is exactly what it sounds like - there is no leader. Every node can receive both read and write requests. Reads are queried in parallel from every node, and writes are also executed in parallel to every node. A successful read/write is defined in terms of the quorum condition: a write is considered successful if at least \(w\) out of the \(n\) nodes return with a success response, and a read is considered successful if at least \(r\) nodes return successfully. The parameters \(w\) and \(r\) are usually chosen such that \(w + r > n\). That way, there is guaranteed to be an overlap between read and write nodes.
The quorum condition might seem like a rock solid guarantee, but the devil is in the details. For example, what do we do if the quorum condition fails? Consider sloppy quorums and hinted handoff. Instead returning an error response for all writes that fail the quorum condition, sloppy quorum means writing to nodes where that data does not necessarily belong as a temporary measure. After the "home" nodes come back online, hinted handoff is initiated to return the data to their original owners.
What about concurrent read + writes, or write + writes? What does it even mean to be concurrent? In this case, two events are concurrent if they do not know about each other. In the opposite case, an event A happens before another event B if B knows about A, depends on A, etc. An algorithm for dealing with concurrent writes on a single replica revolves around tagging with versions:
- Servers and clients both maintain a version number for every key. In the server, update the version number upon every write.
- When a client requests a write, merge together all values that it received on the most recent read, include the version number \(v\), and send off the request. When the server receives this write, overwrite all values with a version number \(v' \leq v\). Do not overwrite values with a newer version number.
In the leaderless framework, how do you resolve stale reads? Say a node goes down immediately before a write - how does this node get updated with the newest value? Two approaches: (1) read repair and (2) anti-entropy process. For (1), upon a read, every node is queried - if one of the nodes returns a stale value, then the node is updated with the newest value. Anti-entropy process is akin to a garbage collector - it's a background process that "cleans up" differences in data.
Continued reading about different consistency guarantees. Monotonic reads guarantees that data reads do not go backwards in time. It's a guarantee against this scenario:
- User A writes and updates a value
- User B reads from one replica and sees the updated value
- User B reads from another replica and sees the old value
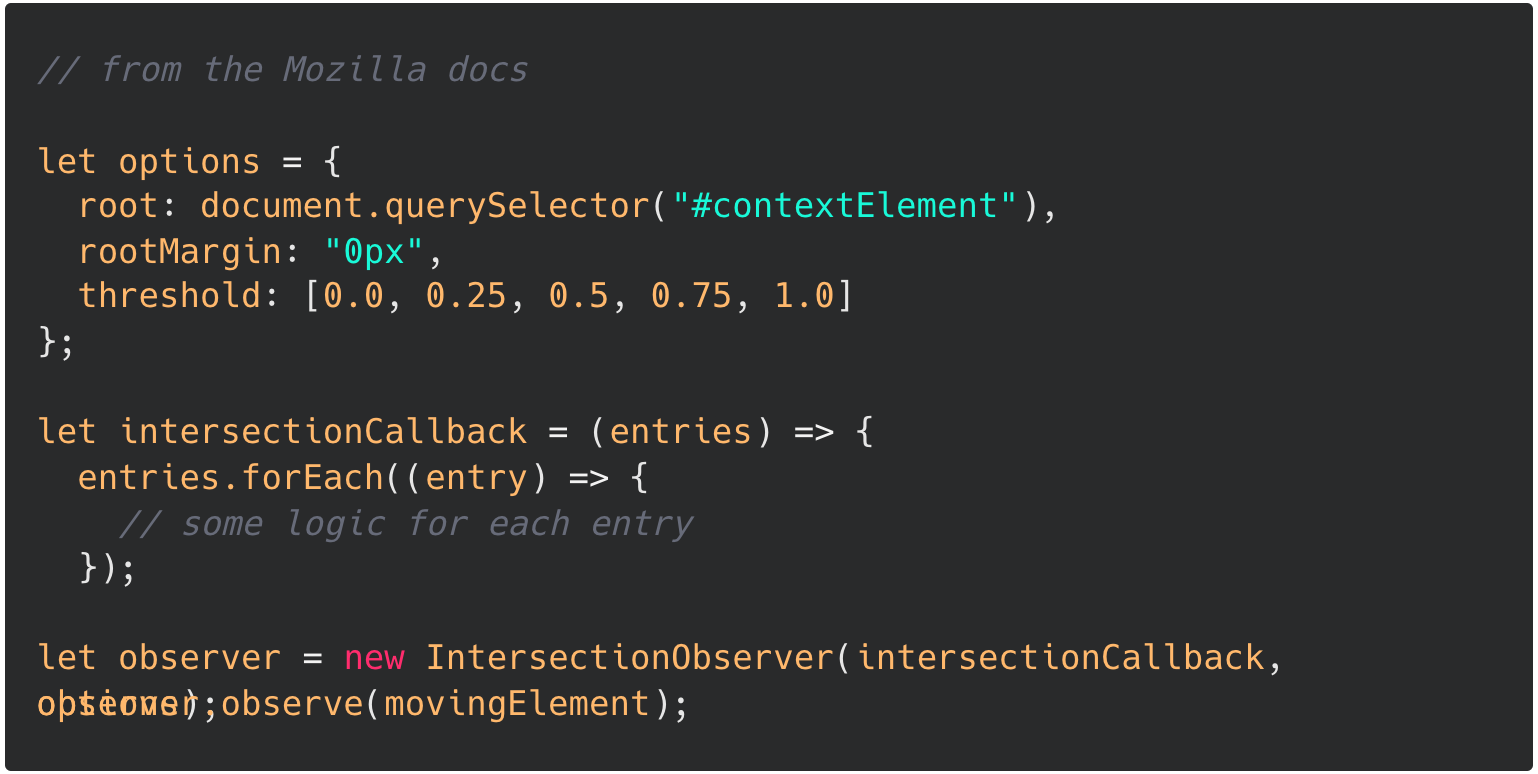
Learned about the IntersectionObserverAPI. You first set up an IntersectionObserver on your "context" element, and set that Observer to watch an element nested inside the context element. The basic usage pattern is:
Read about replication lag. Replication lag is when a follower's data is outdated (compared to the leader's data). Of course, there is always some degree of replication lag - but we need to protect against the tails. What happens when the system is operating at capacity and replication lag grows to an unacceptable length (seconds or even minutes)?
The weakest consistency guarantee regarding replication lag is eventual consistency: it guarantees that the follower's data will eventually match that of the leader's. Clearly this isn't the most useful guarantee - it's the bare minimum.
A stronger guarantee is read-after-write consistency. This ensures that users can read their own writes, immediately after writing them. There are a few ways of implementing read-after-write consistency. The simplest is serving a user's reads for his/her own writes from the leader (e.g. reading your own profile picture after changing it, with the read being served from the leader). But this can quickly become unwieldy if most of the application is self-editable. An extension is to give a time cushion: for \(x\) minutes after a write, serve read requests from the leader. Afterwards, route to any of the other followers.
- college/job applications - imagine submitting an application and not immediately seeing whether or not your application has been submitted
- financial transactions - imagine making a payment and not seeing whether the counterparty has received it or not.
Continued reading about replication, specifically in the leader-follower paradigm. To set up new followers, the general process is to:
- Take a snapshot of the leader's data
- Copy the snapshot to the new follower
- Update the new follower with the data changes that occurred during the copying process
Kleppman talks about four implementations of leader-based replication: (1) Statement-based (2) Write-ahead log (WAL) shipping (3) Logical log-based and (4) Trigger-based.
Statement-based replication is essentially using the leader to "forward" write requests from the client to the followers. For example, a DELETE statement will first be applied to the leader, and then the DELETE request itself will be sent to the followers.
WAL shipping is extending the purpose of the append-only write log as an "instruction manual" for replicating data; if the leader's write-log is followed step-by-step, then the follower should have a copy of the leader's data.
Logical log-based replication is an extension of WAL shipping: instead of using the same log for replication and for the storage engine, why not have two logs for each? The log used specifically for replication is called logical because it is separate from the storage engine internals (the physical representation of data).
Trigger-based replication is used when replication needs to be more customized. For example, you may want to replicate only a subset of the leader's data. In this case, you can set up a trigger to run custom application code on a specific write request.
As you scale, the systems built around your data should scale also. The easiest extension is to replicate your data. The main problem to be solved, again, is that data evolves. How is this evolution managed when there are multiple copies of your data?
In the leader-follower paradigm, one replica is designated as the leader, and the rest of the replicas are followers. On writes, the leader sends out the changes made to its followers, who subsequently apply the changes to themselves. This means that writes can only be submitted to the leader, but reads can be queries on any of the replicas.
useEffect is for creating an escape hatch to an external service/component. TBH, a more accurate name for this function would be useSideEffect, in my opinion.
Learned about how data is passed around. There are a couple problems with passing data between different machines: (1) translation between in-memory and bytes (2) things always change, including the shape of data. I've encountered the second problem a lot in my projects; I sometimes delete the entire database when I decide that my schema needs another field.
In-memory \(\rightarrow\) bytes is called serialization/encoding, and the inverse operation is called deserialization/decoding. JSON and XML are examples of text-based encodings, and Protocol Buffer, Thrift, and Apache Avro are binary encodings. Like anything, there are tradeoffs:
- Textual encodings are human-readable, but they are not very space-efficient. Binary encodings are the opposite.
- JSON and XML have good text support (Unicode), but no support for binary strings. Binary strings are usually encoded as base64 strings for JSON and XML, which means a 33% increase in data size.
Top of mind for any serialization/deserialization framework is how well it accomodates change. It's impossible to foresee in totality what data fields will be needed, so a serialization framework needs to support backward/forward compatibility out-of-the-box.
A couple patterns that I've noticed with binary encodings like ProtocolBuffer and Thrift:
-
Field names are given numeric "field tags" - sort of like pointers. Field names can change, as long as the associated field tag doesn't change.
I bet all the problems that are common with pointers apply here.Two pointer problems that come to mind are null references and dangling references.
- Null reference. If the received encoding contains an unrecognized field tag, then it is just ignored (at least for ProtoBuf).
- Dangling reference. If the received encoding contains a field that used to be recognizable, then it is ignored just the same.
-
Some bits are used to describe how much data is in the following bits. This comes up everywhere - I've seen this pattern in Git's tree encoding also.
Advantages / disadvantages of this?The main advantage is that you have more information at the outset. If you know that all your field names are 10 characters long, then you can be sure that all the fields in the received data must also contain fields that are at most 10 characters long. The disadvantage is waste of space..?
Apache Avro introduces an interesting insight: reader and writer schemas don't need to be the same. As long as they are compatible, there should not be any problem. Avro compares the writer and reader schemas, resolves the differences between the two, and transpiles one into the other. I see the Avro insight as an application of "separating data from code". That's one of the core ideas behind parser generators - separate the "shape" of the language from the code that parses it, and you will instantly be able to support a wider variety of languages. You are trading off more dynamic support for less stability in your data models; this is to say that Avro is best for applications with dynamically generated schemas.
The interesting thing with Apache Avro is that there are no field names or tags at all. Instead, the field tags/names are implicit in the order.
Why are we talking encoding/decoding at all? Because data moves around. Kleppman talks about three models of dataflow:
- Via database: encoding responsibility is assigned to the process that writes to the database; decoding responsibility is given to the process that reads from the database.
- Via service calls: client encodes request, server decodes it, server encodes response, client decodes response.
- Via asynchronous message passing: messages encoded by sender and decoded by receiver.
A couple buzzwords:
- REST (Representational State Transfer): a design philosophy for designing web services.
- SOAP (Simple Object Access Protocol): another design philosophy for designing web services.
- RPC (remote procedure call): call to a remote service as if you are calling a local function.
- SOA (service-oriented architecture): a design philosophy for building web service applications.
Learned about OLAP (OnLine Analytics Processing) vs. OLTP (OnLine Transaction Processing). The access patterns for using a database for business execution are different from using it for business intelligence. For execution, the main read pattern is fetching a small number of records, whereas the same for intelligence is reading in bulk. The main write pattern for execution is random-access, low-latency writes, but for intelligence, it is bulk import (extract-transform-load) or event stream. A small terminology thing: "data warehouse" is to OLAP as "database" is to OLTP.
The difference between OLAP and OLTP is akin to the difference between browsing (OLAP) and searching (OLTP). For a browsing experience, you want to cast a wide net and get as many results as possible that might relevant. For searching, you want fast, pinpointed search results.
Because of this chasm in access patterns between OLAP and OLTP, the data models for the two are different also. The data models for OLTP depend on the application, but most OLAP systems stick to the star schema. The star schema consists of a fact table at its core, and the fact table contains foreign key references to other dimension tables. Kleppman has a nice explanation here: "As each row in the fact table represents and event, the dimensions represent the who, what, where, when, how, and why of the event."
Also learned about column-oriented storage. For OLAP workflows, you usually don't need all the facts about an event - you just need a few. What if we stored by column instead of by row? For columns with a finite number of discrete values known beforehand, we can apply bitmap encoding and/or run-map encoding. If there are \(n\) rows and \(k\) discrete values, then construct a binary \(n \times k\) matrix with 1's denoting which value is located in which row. If there are long "runs", then we can further compress by just counting the length of the runs.
Also learned about different encoding formats, especially binary encodings.
Learned about BTrees. The core idea of BTrees and SSTables is the same: sort the keys. But instead of using variable-sized segment files, BTrees use fixed-size pages. Searching for a key begins with a root of key ranges that contain references to other branches in the tree - eventually you will reach a leaf node that contains the corresponding value in-line, or contains references to other pages (in the case that the value for a key spans multiple pages).
Learned about popular design patterns in web development and Javascript in general. I found this website with common design pattersn for Javascript and React, and I went searching for more in web.dev.
Two acronyms to keep in mind: FCP (First Contentful Paint) and TTI (Time to Interactive). FCP is the elapsed time from when the page starts loading to when any part of the page's content loads. TTI is the elapsed time from when the page starts loading to when the page can respond to user input quickly. I likely won't be needing to care about this any time soon - but good to know.
I also learned about the Command pattern and the Mixin pattern.
The Command pattern is for separating an action from the object that executes the action. It's similar in spirit to separating data from the algorithm. Instead of tying methods to a class, you can dispatch the method from a separate class whose sole job is to execute the command using the data from an instance (Did what I just said make sense?). Here's a small example from the patterns site that illustrates:
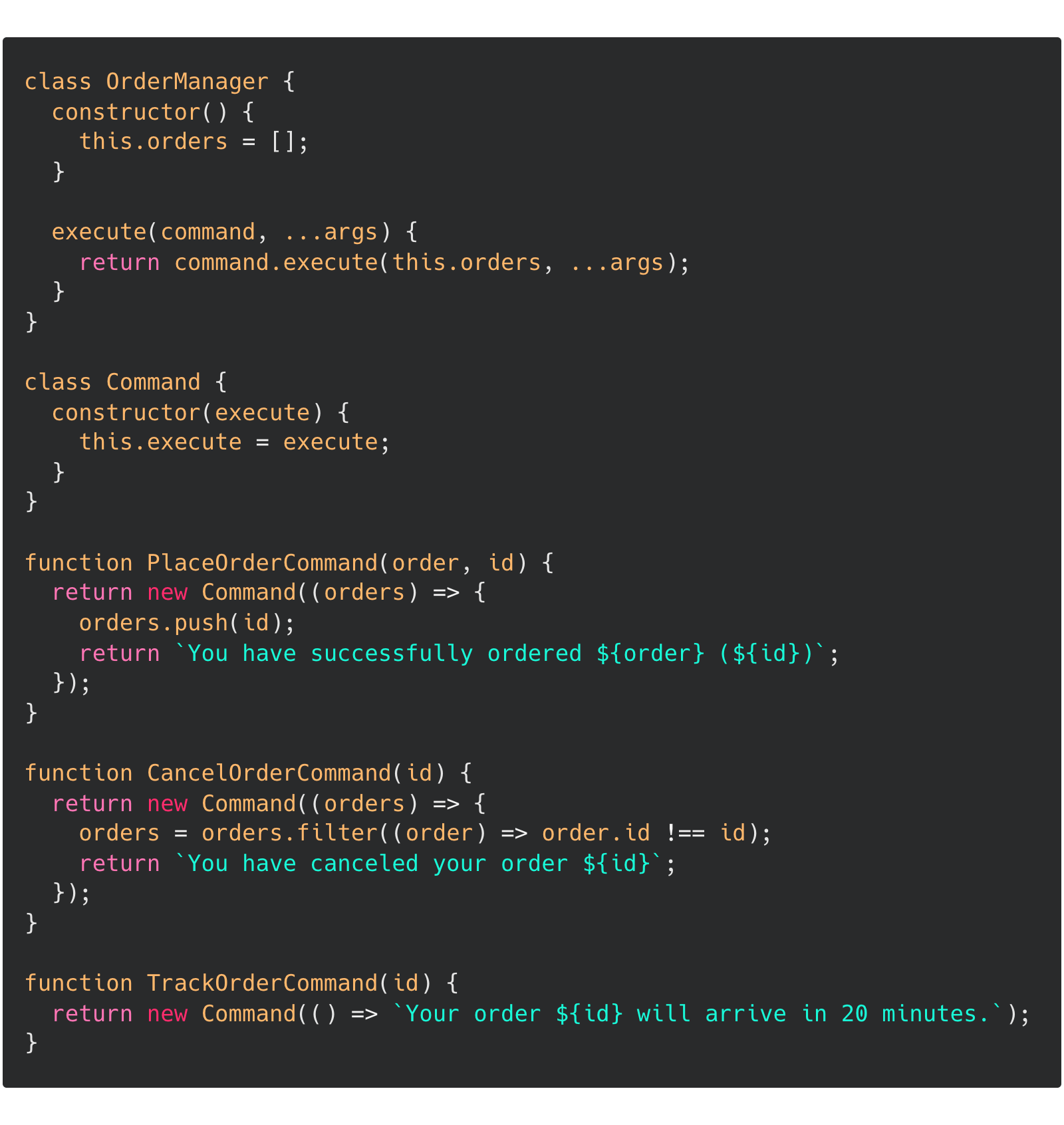
The Mixin pattern is way cooler. In OOP, objects can be inherited ("is-a") or composed ("has-a"). Inheritence is used to extend a class by adding new functionalities, but composition is more flexible in that it allows you to use functionalities of other classes. Mixins are similar to composition in that sense - you can mix-and-match components and properties together.
A real TIL - something like Cyberpunk exists already! It's called Write Reason.
First pass at reading a third of the second chapter of DDIA.
Start off with the simplest key-value store you can think of: a text file. Read from the text file by searching through character by character. Write by appending to the end of the file. An advantage to this approach is that writing is extremely simple and fast. The main disadvantage is that reading takes awfully long. How can we tradeoff some of the simplicity of writes to offload the complexity of reads?
Iteration two: an in-memory hash table, paired with a log-structured file on disk. The hash map maps keys to a byte offset, which points to the memory location of the corresponding key:value pair in the log-structured file. When you do a get operation, look up the key in the hash map, and you have the location of your key:value pair. When you do a set operation, hash the key, get the byte address of the end of the file, and write to the end of the file. A problem with this approach is that key:value's are only ever appended to the file, so you want some mechanism to "garbage collect". Segmentation and compaction are the answers to this. Segmentation is when you segment your log file - once it reaches a limit, close it and open a new log file. Compaction is a garbage collection action taken on segment files: you throw away duplicate keys in the log, and keep only the most recent updates for each key.
Two problems with the in-memory hash table approach: (1) the hash table needs to fit in memory, so this approach isn't feasible for applications with a large number of keys (2) range queries suck because it's akin to going back to Iteration one - you have to go over every key in a range.
Iteration three: SSTables & LSM-Trees. SSTables expand on Iteration two with a simple, but beautiful step: ensure that the key:value pairs in a segment file are sorted by key.
Learned about how the files in Electron are connected. The entry point is main.js, as defined in the main field in the package.json file. Because main.js runs in a NodeJS process, you can use CommonJS modules. The job of the main.js file is instantiate a BrowserWindow, which is connected to the renderer process. The BrowserWindow instance references an HTML file - this HTML file can reference a Javascript ES module. For any module imports for an ES module, you need to use the directory that the HTML file is located in as the base directory.
Datalog is a graph database! That's pretty cool.
More specifics about Git.
The Git object database is append-only, so everything that you've ever added or committed to Git will be there.
The hash of a Git object is agnostic to what kind of object you're dealing with. Concantenate the format (blob, tree, commit, tag), an ASCII space, the size of the object data encoded into ASCII, the null terminator, and the object data itself. Hash this string, and you've got your object hash! The first two characters of this hash gives you the directory that this object will live in, and the rest is the key to the object.
Big endian is most significant byte first (how we normally read numbers - left-to-right). Little endian is most significant byte last. Remember that big/little endian is a byte-level ordering, not a bit-level ordering - the bits inside each byte are still in left-to-right order.
Unicode is a mapping from characters to a hexidecimal number prefixed with U+ called a Unicode codepoint. It standardizes characters on every machine. UTF-8, UTF-16, UTF-32 are encodings of Unicode because Unicode needs to be converted into bytes in order to store or transmit string data.
Blobs can be anything - almost everything in Git is a blob. A blob is like a value-value store.
Commits are like ledger blocks in the blockchain. They mark a state in the file system + files and also point to the parent of the last state. Commits themselves are referenced as blobs.
Trees associate blobs to paths. They have a relational-database-esque format: each row is a 3-tuple, with columns for Mode, SHA-1, and Path.
Mode is the file/directory's permissions. SHA-1 is the file/directory's blob hash. Path is the file/directory's path in the working directory. If the entry in Path is a file, then the SHA-1 column refers to a file blob. If the entry in Path is a directory, then the SHA-1 column refers to a tree blob. This means that "tree table" only goes one layer deep - you can't have a tuple of (mode, sha-1, src/dir1/dir2/dir3/dir4).
It instantiates a commit in the working directory. The goal is to take the information inside the commit (i.e. the state of the file system at the time) and copy that data into the working directory.
If objects are just a series of SHA-1:hexadecimal identifiers, how can we ever access them? After all, commits and trees are also saved as objects. We need an "entry point".
References solve this problem.
References live in .git/refs, and this folder holds the SHA-1 identifier of an object.
Tags are just named references, and they live in .git/refs/tags/.
A branch is just a reference to a commit which is to say that a branch.. is just a tag. The current branch is referred to in a ref file outside of .git/refs; there is a file called .git/HEAD that holds the HEAD tag.
The index kicks in when you create a commit. The index file is kind of like an intermediary between the git database and the working directory; the index file is essentially the staging area, where you can translate from the working directory to the git database. It holds all this useful metadata.
I read through a bit of the first chapter of Designing Data-Intensive Applications. I learned about the different types of databases, the two big ones being relational databases and document databases. Relational databases are databases that store data as tuples. Document databases have more flexibility - they can store data as schemaless "documents", which is to say that they can store nested structures instead of the flat tuples of relational databases.
In storing one-to-many relationships, document databases are probably a better choice than relational databases. Take a resume database as an example. How would you store resumes in a relational database? Each row could represent a candidate's database... but candidates usually have multiple jobs, hobbies ,etc. Are you going to create a column for each experience/hobby? Are you going to allow arrays in columns? If you allow arrays, how will you search for a specific entry inside the array? The problem quickly gets complicated. For document databases, however, the structure unfolds quite naturally: encoding as JSON is really simple and intuitive.
For many-to-many or many-to-one relationships, document and relational databases aren't all that different. Relational databases have unique identifiers called foreign keys. Document databases have document references.
Some advantages and disadvantages. Nested information in document databases means that the more nested your schemas are, the more work you have to do to retrieve deeply nested items. Joins are also harder in document databases, which could be a problem if you have a use case that has many-to-many relationships. The tradeoff here is that the data models that can be used for relational databases are restricted, where as document databases are much more expressive.
Document databases being called schemaless is a misnomer. You can have schema on write and schema on read. Schema on read is when the structure of the data is implicit, and schema on write is when the structure is explicit. Document databases are schema on read, whereas relational databases are schema on write. A helpful analogy here could be schema on write is to static type checking as schema on read is to dynamic type checking.
Storage locality is high when the number of queries you need to make to read data is small. When you don't normalize your data at all (everythinng in one big table), then you have high storage locality. High storage locality is not necessarily a good thing: even when a small part of the data needs to be changed, the entire thing needs to be rewritten.